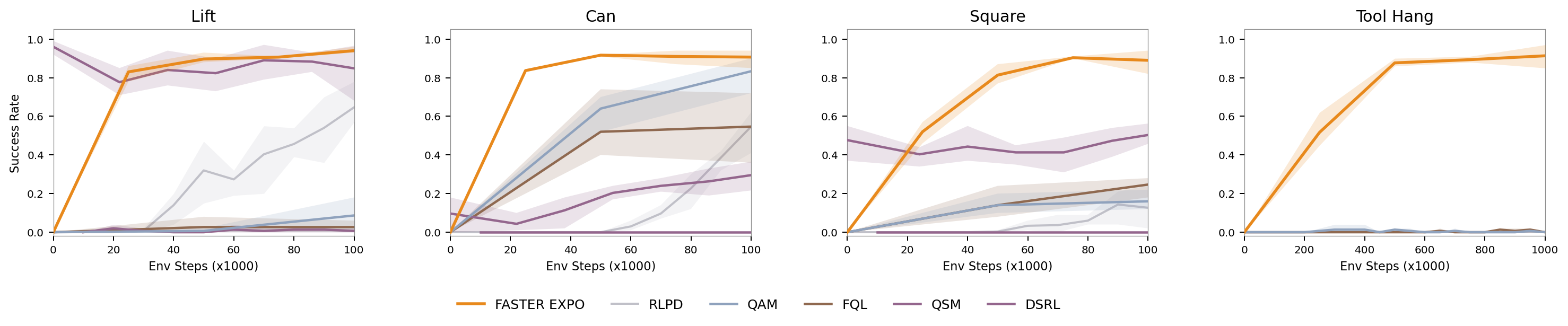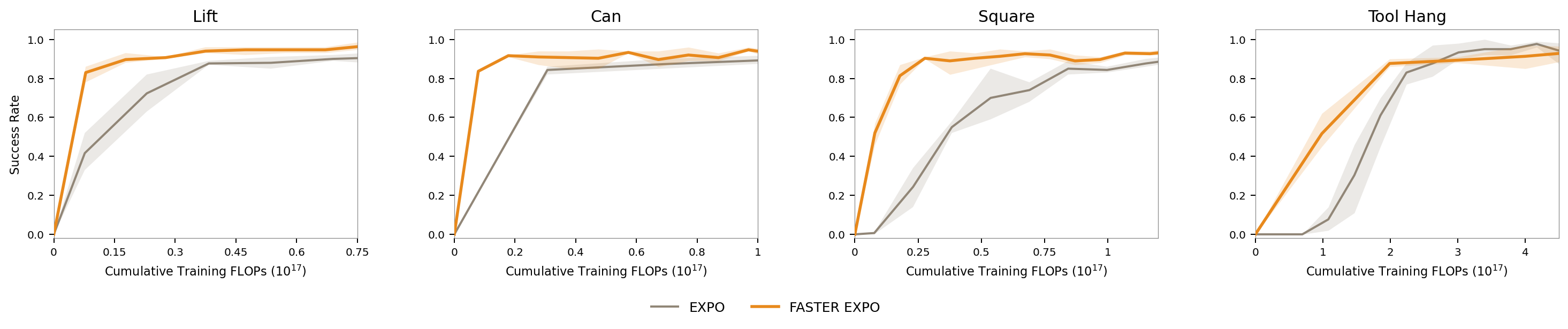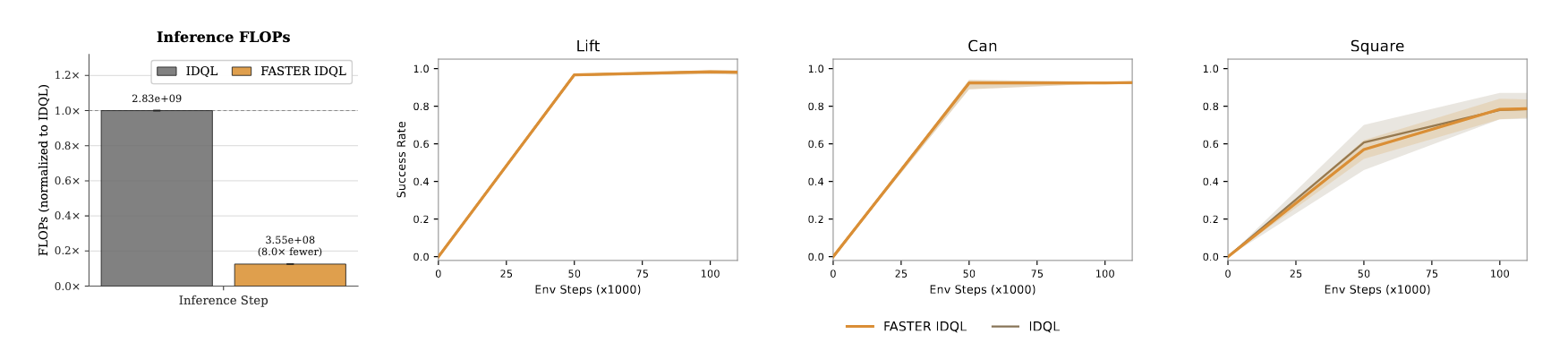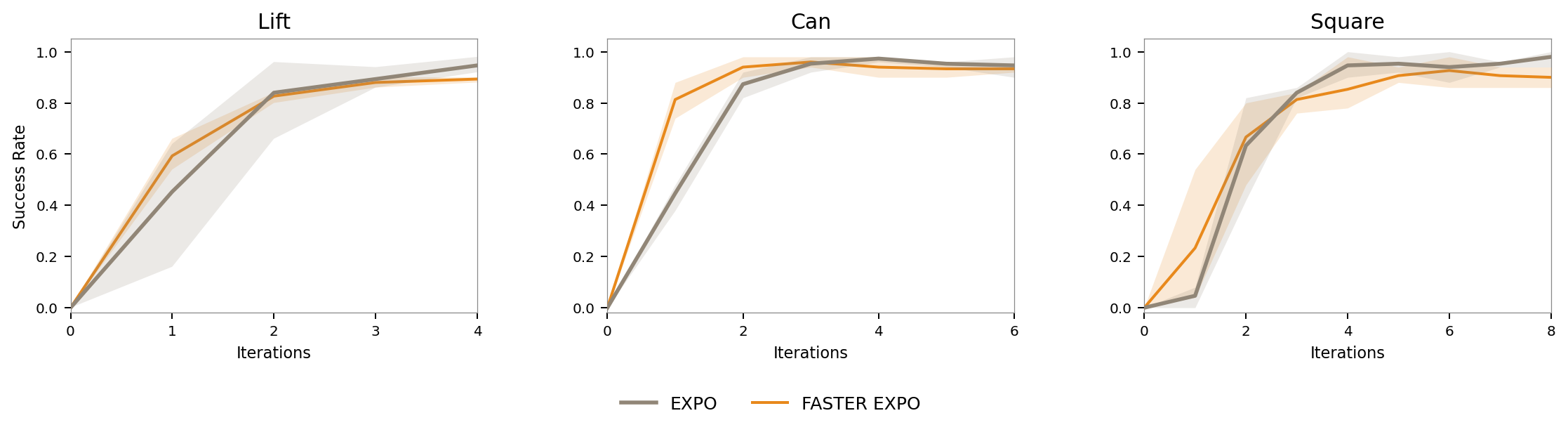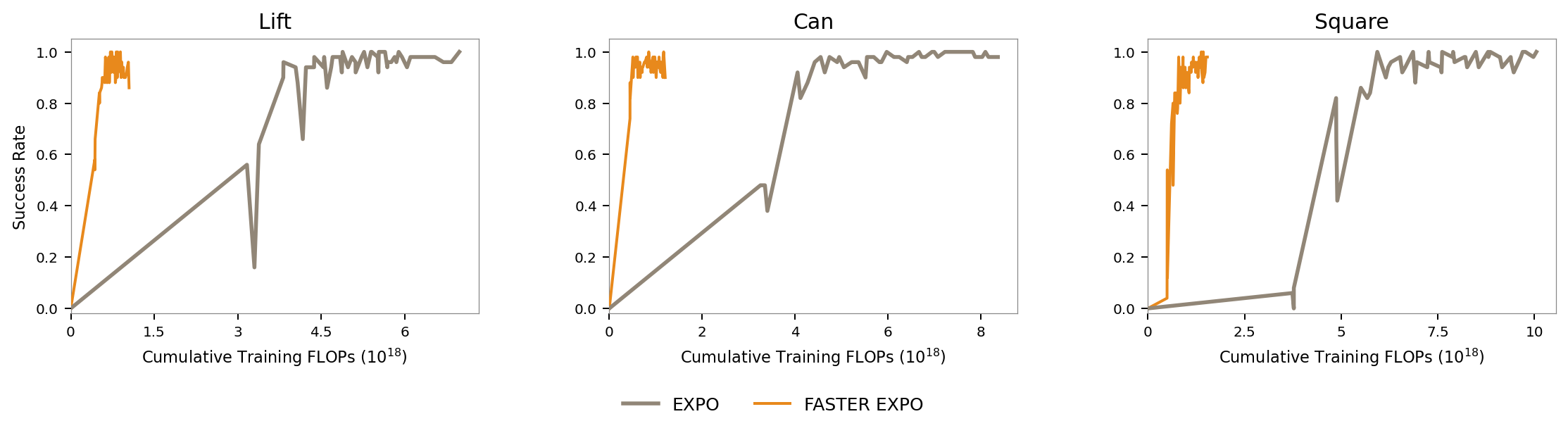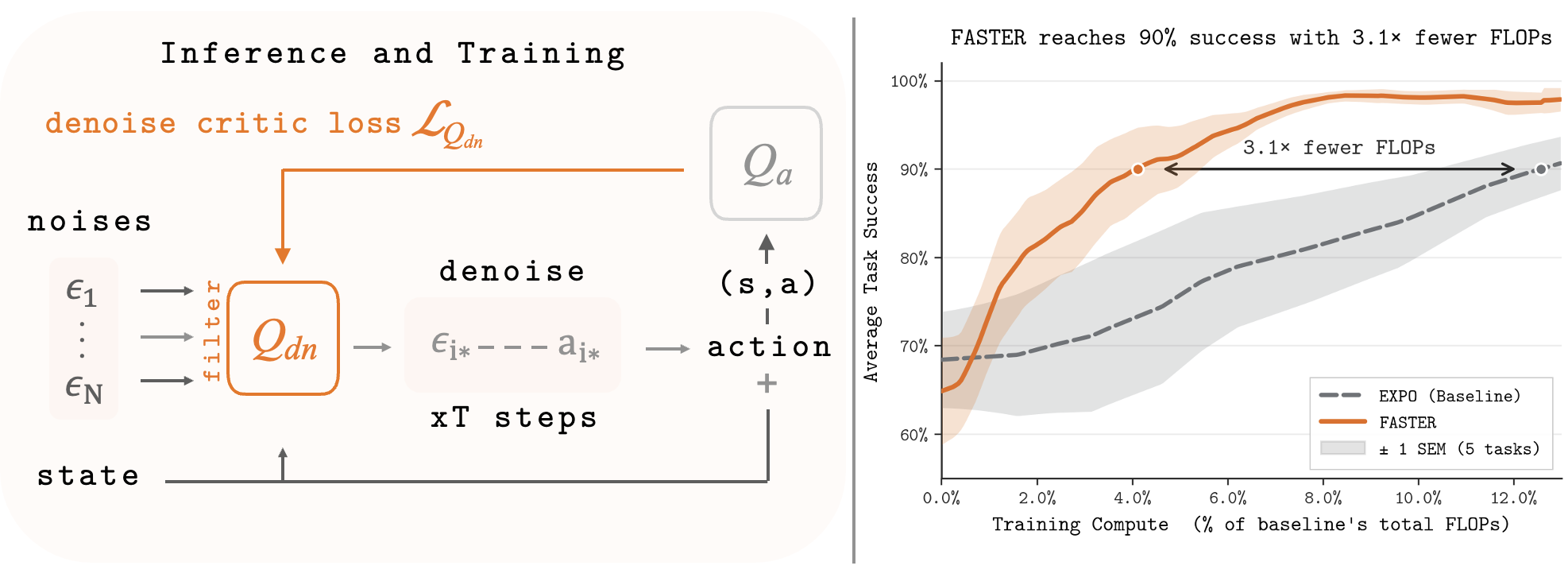
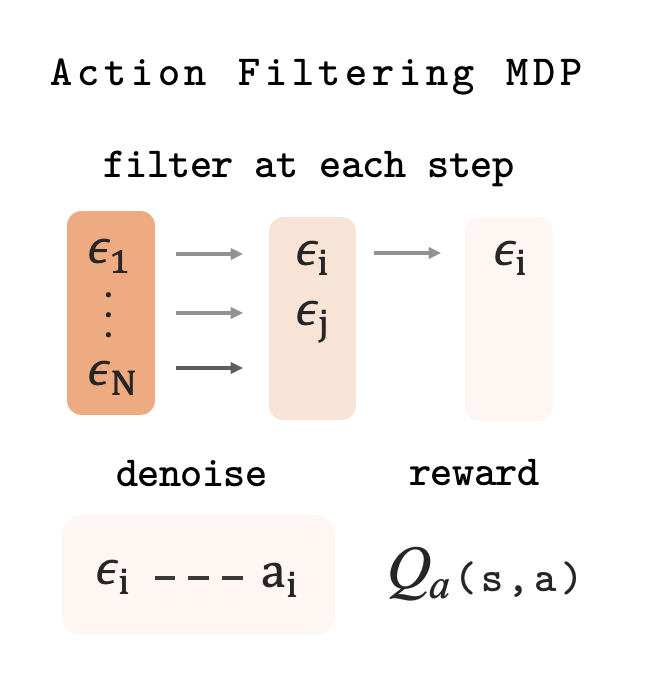
Modeling Action Denoising as an MDP
Diffusion policies generate actions by iteratively denoising random noise — but not all noise candidates are equally promising. Rather than waiting until denoising is complete to pick the best one, we want to identify and discard poor candidates early, saving computation and improving quality.
To do this, we frame the denoising process as a sequential decision problem: at each denoising step, a learned policy looks at all surviving candidates and decides which ones to keep. Unpromising candidates are dropped early; the best survivor is ultimately executed in the environment.
States. At each denoising step, the policy observes the current environment state, how far along denoising has progressed, and the current (noisy) form of each surviving action candidate.
Actions. The policy decides which candidates to keep and which to discard — at least one must always survive.
Transitions. Surviving candidates are denoised one step further. The process ends when only one candidate remains or denoising completes, at which point the best survivor is executed.
Reward. Non-terminal steps receive zero reward. At termination the reward is Q value of the surviving action in the environment.
Learning the Filtering Policy
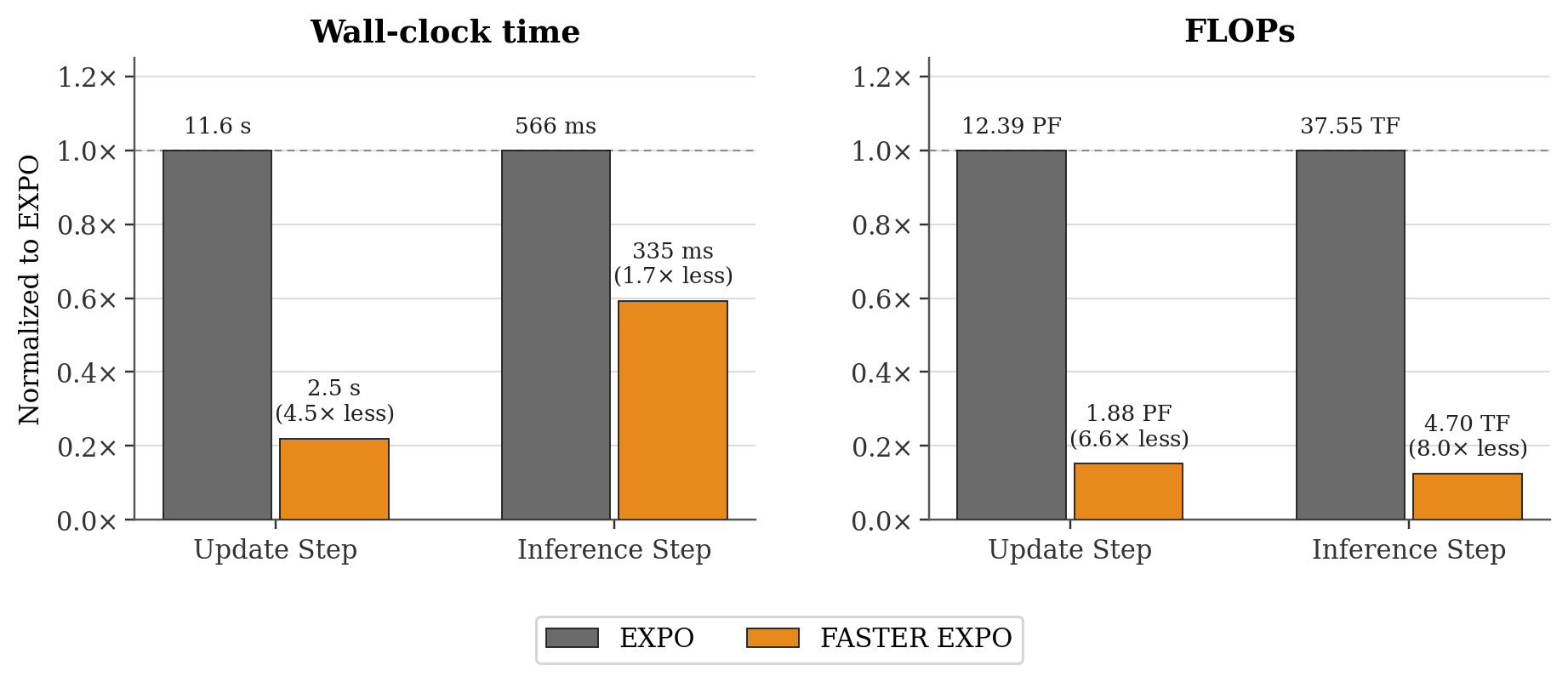
We train a critic that estimates the quality of any filtering decision at any denoising step. The critic is trained with standard temporal-difference learning — it bootstraps from its own future predictions, gradually learning to predict which early filtering choices lead to high-quality final actions.
At test time, we start with a pool of random noise candidates and progressively filter them down using the learned critic, until a single candidate remains. That candidate is fully denoised and executed as the final action.
Simplifying to a Single Filtering Step: In practice, we find that instead of filtering candidates throughout the entire denoising process, iltering candidates at the noise level—which is the cheapest instantiation computationally—achieves performance equivalent to fully denoising all action samples and selecting the highest value action.